Table Of Contents
Intro Link to heading
In the last few months I have spent a lot of time learning about Generative AI, specifically focused on LLM’s. To date I have mostly focused on understanding how they work, especially some of the most famous LLM’s such as GPT, LLama, and BERT. As I have gained a better understanding of how these models work, I have been thinking about what flaws LLMs have and how they can be mitigated. This post will be focused on hallucinations, but I will likely do other posts in the future on some of the other common issues with LLMs.
This post is mostly a summary of the excellent information contained in Siren’s Song in the AI Ocean: A Survey on Hallucination in Large Language Models1 by Yue Zhang, Yafu Li, Leyang Cui, et al.
Definition Link to heading
So what exactly is hallucination? Wikipedia’s page on hallucination2 defines it as “a response generated by an AI which contains false or misleading information presented as fact”. From an end-user perspective of popular services like ChatGPT and Github Copilot, hallucinations are problematic because if the user doesn’t know the subject matter they are using an LLM for they will just believe what was generated. This can lead to all sorts of real world impact. For instance Forbes3 reported on a case where a lawyer was found to have used ChatGPT to generate cases that were presented in course in a personal injury filing against an airline. All of the cases that the lawyer used to show precedent were found to be false. According to the Courthouse News Service4, both lawyers involved in submission of fake cases were fined $5000. Steven Schwartz who claimed that it never occurred to him that ChatGPT would make up cases.
Hallucinations occur in other natural language generation models, which has been studied for years. However, LLM’s offer additional complications in the types of hallucinations, detection strategies, and mitigation techniques. LLM’s typically train on a massive amount of tokens, compared to previous language models. For instance the LLama 2 model by Meta is trained on 2 trillion tokens5. The size of their training data, wide array of subjects they cover, and the believability of generated data all make hallucinations more problematic than with previous language models.
Types of Hallucination Link to heading
Siren’s Song in the AI Ocean1 defines three types of hallucinations common in LLM’s:
- Input-conflicting: LLM’s generate content conflicting with the users input
- Context-conflicting: Generated content that conflicts with previously generated content (in the same session)
- Fact-conflicting: Generated conflict is factually incorrect, or at least not consistent with world knowledge
Input-conflicting hallucinations occur when there is a misunderstanding of the user’s intent between the task requested and the task input. An example of this would be the following:
- Input: Please summarize the following: My dog Athena is an Alaskan Malamute and Labrador Retriever mix. She enjoys walks, bones, and car-rides. Athena likes to guard us by warning anyone that comes to our house, by barking at them.
- Response: Athena is an Alaskan Malamute that enjoys walks, bones, and guarding.
This is input-conflicting because the input had said Athena is an Alaskan Malamute and Labrador Retriever mix. The summary generated is generally correct, but fails to be completely correct. Since this hallucination is driven from a user’s input, it may be easy to detect.
A context-conflicting hallucination typically occurs when the generated output is too long, as the LLM either loses track of the context or is unable to remain consistent through the whole response. This potentially occurs due to limitations in LLM’s memory. An example of context-conflicting hallucination would be when an LLM suddenly changes a subject’s name.
Fact-conflicting hallucinations can occur from many different sources, for instance from factually incorrect pre-training data or a misalignment between pre-training data and task fine-tuning. Detecting fact-conflicting hallucinations and mitigating them has been the largest focus of research, so it has the most potential ways of detecting and mitigating issues. A good example of a fact-conflicting hallucination is the fake cases used by Steven Schwartz3.
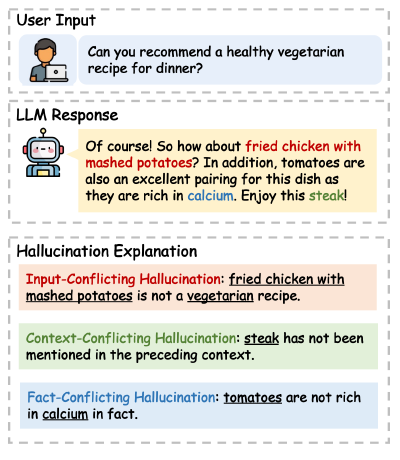
The LLM-hallucination survey1 has a good example that demonstrates all three types in the same response:
Evaluation Techniques Link to heading
Evaluation techniques are grouped broadly into truthfulness of LLM generated content and an LLM’s ability to discriminate factual statements. A lot of the existing techniques use humans to validate generated responses in some way or another. For instance a handful of techniques involve creating a factual dataset, each prompt is given to the LLM and then evaluated based on the expected facts. TruthfulQA, FActScore, HaluEval, and FACTOR are all examples of this. They differ in what data is generated and the metrics for which the LLM will be evaluated.
A good example of a human based generative evaluation is TruthfulQA6. With TruthfulQA the researchers created a dataset of 817 questions that span 38 categories. Each question has a set of true and false reference answers, with sources to backup their truthfulness. The questions were evaluated by 2 outside experts to ensure their validity. To be considered true a response has to avoid asserting any false statements. One way of getting a high score is to give non-committal responses such as I don’t know, which are considered true for the evaluation. Each question was given to the models and a human participant (who had access to the internet). The human was able to get 94% of the questions correct, whereas the best model (GPT-3-175B) only got 58% true answers.
These human based evaluation techniques so far have proven to be the best for judging LLMs, but they are labor intensive to create. This has led researchers to look for ways to use models to evaluate models. The same TruthfulQA paper trained a GPT-3-6.7B model to classify answers as true or false, based on the collected human annotations. This model is able to get 90-96% validation accuracy, depending on the data given. This shows promise for establishing a better way of measuring LLM’s for validity (and therefore lacking hallucinations).
For discrimination techniques models can be evaluated directly using plain ol’ accuracy. This still requires the creation of a dataset, which can be labor intensive. However, one simple way of determining hallucinations in an LLM is to just have it answer many multiple-choice questions, where we already have the answer.
Mitigation Link to heading
Mitigation of hallucination can be done at many stages of an LLM, with some stages having easier or more effective ways of mitigating hallucinations.
Mitigation by phase:
- Pre-training: This is particularly challenging with LLM’s due to the shear size of data. Most efforts to mitigate hallucinations here center around trying to curate input data, only using high quality sources. For instance, only using Wikipedia or text book sources. As input data sizes grow to produce better models this alone isn’t enough however. Llama 2 used upsampling with highly trusted data sources in order to have enough training data, whereas other models have tried similarity to trusted sources.
- Fine-tuning: Since fine-tuning is typically done on much smaller datasets than pre-training a handful of researchers have sought to mitigate hallucinations by having higher quality fine-tuning datasets. This is done similarly to pre-training curating. However, there are many issues with doing this such as quality of pre-training datasets, differing knowledge boundaries between pre-training and fine-tuning datasets, and the potential of behavioral cloning. Behavioral cloning is the tendency of LLM’s to mimic the format of their fine-tuning data answering without questioning whether the knowledge is outside its knowledge boundary.
- Reinforcement Learning from Human Feedback (RLHF): which seeks to solve hallucinations by using a reinforcement model that has rewards based on human preferences to optimize an LLM during fine-tuning. Having the human preferences be based on honest answers can significantly reduce fact-conflicting hallucinations. However, this approach can lead to over-conservative models that will not answer despite definitely having the information to do so.
- Inference: Mitigating hallucinations at this step has a broad array of solutions that have proven reasonably effective. Techniques that have been developed for inference based mitigation include: using external sources to validate and correct model output, decoding strategies which favor generating more factual content (such as CoVe and ITI), using the uncertainty of each layer in a model to chose more correct responses, better prompt engineering, and finally multi-agent interaction.
From my limited knowledge it seems like addressing hallucinations at RLHF or inference seems the best approach, for those that are leveraging large base models trained by others. Solving it at inference seems to offer the most techniques and flexibility. I think this is how ChatGPT and other LLM services have addressed toxic content as well, but that will be another post.
Conclusion Link to heading
With the success of large language models in a wide array of subtasks more solutions are being created using them everyday. Knowing the pitfalls of these models is crucial to ensuring quality of experience for end-users and can have real world impacts. In this post I explored one pitfall of LLMs, that is hallucinations. Hallucinations are a big challenge for LLMs due to their size, span of content, and how believable generated responses are. There is a lot of research going into detecting and mitigating hallucinations within LLMs, however there is still a lot of more needed to find better ways. Currently, using an LLM to evaluate another LLM for truthfulness seems like a promising way of evaluating models for hallucinations. This coupled with more limited human-evaluation seems like the safest approach. There are many ways of mitigating hallucinations, some of the most promising are done at inference time. This gives the most flexibility in terms of reducing a models hallucinations overtime.
References Link to heading
https://en.wikipedia.org/wiki/Hallucination_(artificial_intelligence) ↩︎
https://www.forbes.com/sites/mollybohannon/2023/06/08/lawyer-used-chatgpt-in-court-and-cited-fake-cases-a-judge-is-considering-sanctions/?sh=5e404ef27c7f ↩︎ ↩︎
https://www.courthousenews.com/sanctions-ordered-for-lawyers-who-relied-on-chatgpt-artificial-intelligence-to-prepare-court-brief/#:~:text=Steven%20A.,the%20artificial%20intelligence%2Dpowered%20chatbot. ↩︎
https://ai.meta.com/resources/models-and-libraries/llama/#:~:text=Llama%202%20models%20are%20trained,1%20million%20new%20human%20annotations. ↩︎